idea 如何配置 java 的面包屑导航
本文共 138 字,大约阅读时间需要 1 分钟。
面包屑导航: 可以展示当前光标所在的方法, 用于快速确认当前所在方法和定位当前所在方法的开头
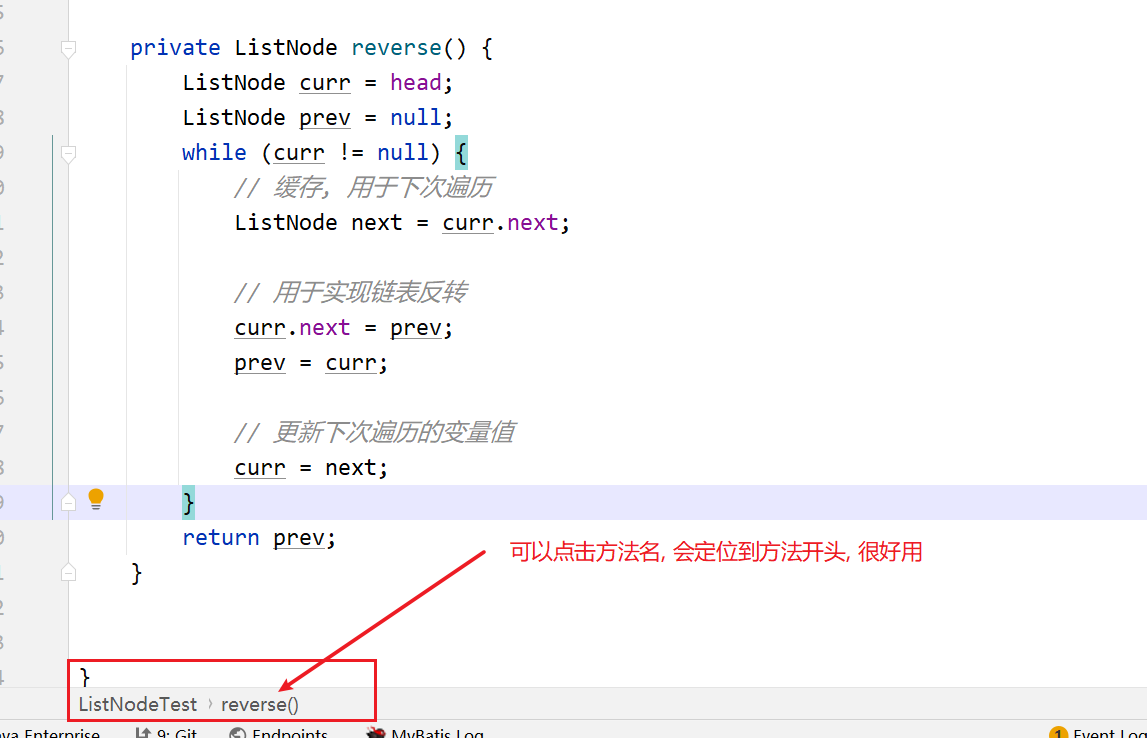
在之前的版本中, idea 该面包屑导航是开启的, 在 2020 版本后, 默认是关闭状态
editor > general > breadcrumbs > 勾选 java > ok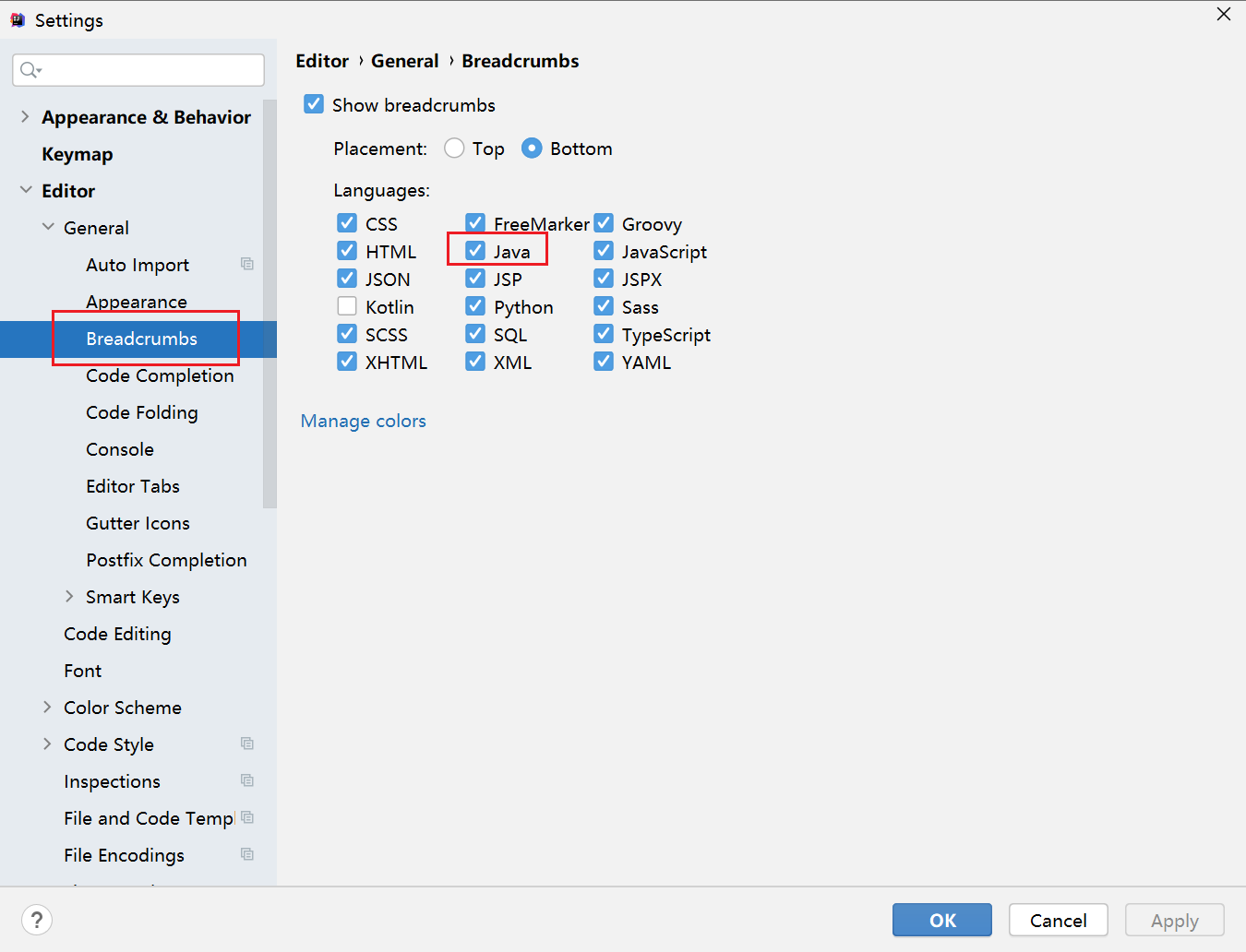
转载地址:http://gpcg.baihongyu.com/
你可能感兴趣的文章